Agents Can Reason. They Still Can't Really Search.
Agents have a search problem across the whole stack: web search, RAG, tool discovery, skills/workflow loading, and even context compaction.
Modern agents can write code, call APIs, draft a memo, and pass a benchmark. That part is real. Put one in front of a clean, well-scoped task and it can look genuinely magical.
Then you ask it to do something normal.
Find the pricing page for a competitor that just relaunched their site. Pull a clause from a regulatory filing hidden inside a government portal. Answer a question that requires connecting facts spread across three internal docs written by people who already left the company. Deploy to an infrastructure setup with custom flags, a weird CI config, and a workaround for a flaky pre-push hook that somebody documented once in a Notion page nobody can find. Or just pick the right tool from a catalog of sixty.
This is where things start falling apart.
Not because the model suddenly forgot how to reason. Not because the prompt is missing some sacred incantation. The failure is more basic than that, and once you see it, you start seeing the same bug everywhere.
Trying to get OpenClaw agents to do useful work is like trying to win at trading crypto - only the top 1% win.
— Brad Mills 🔑⚡️ (@bradmillscan) March 2, 2026
The rest of us end up being the lobster meat for the host in the shell.
OpenClaw agents are terrible at executing complex multi step processes that require delegation.…
The recurring bottleneck is search
Search here means one simple thing: before an agent can reason well, it has to find the right thing.
That "thing" might be:
- a source on the public web
- a useful chunk from your private docs
- the right tool or MCP action
- the right skill or procedure
- the relevant part of a long context window
Agents fail on real-world tasks because they keep running into this problem in different places. If any one of those breaks, the whole task usually breaks with it.
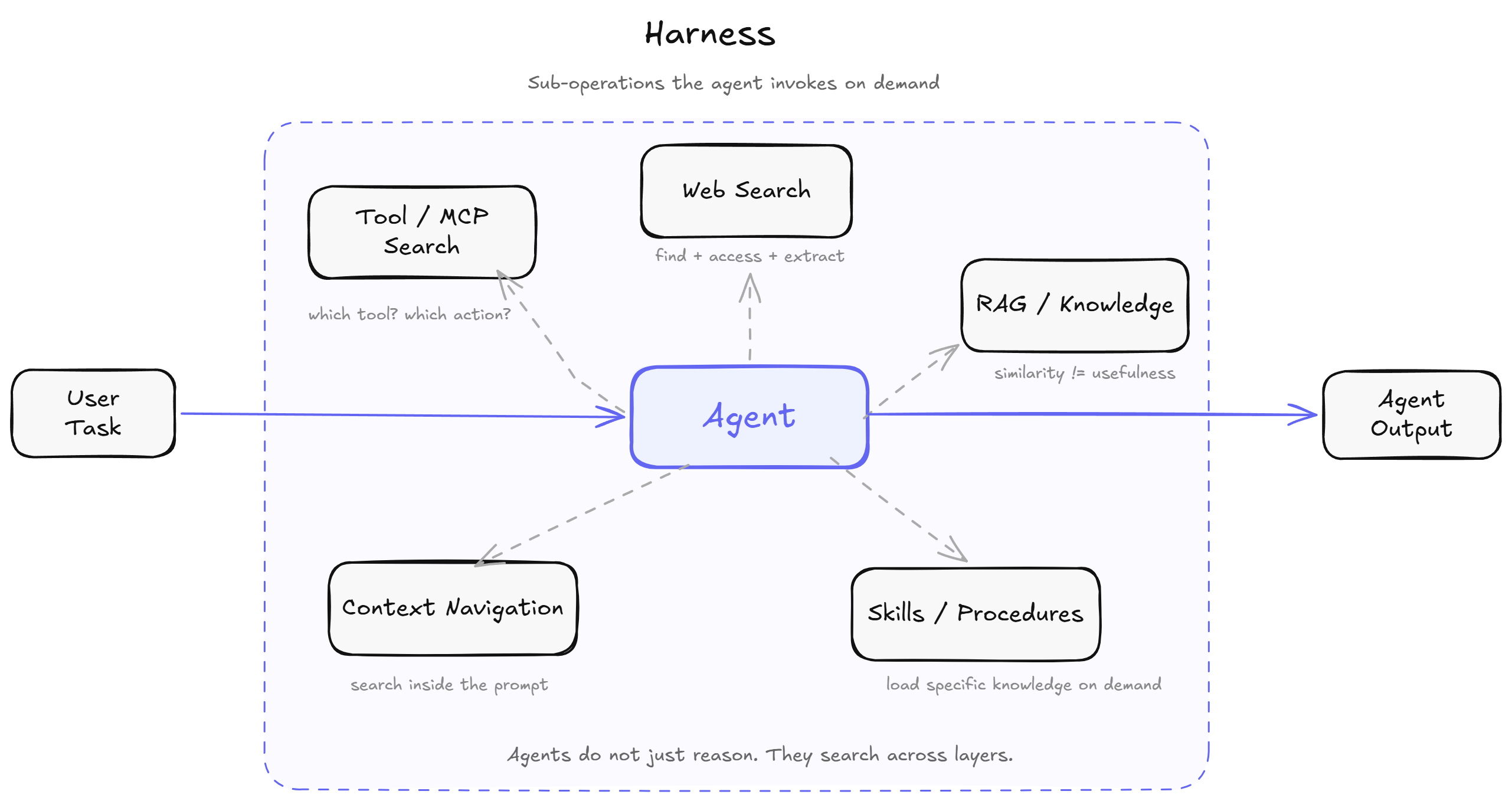
You can see the same pattern in a few different places:
- web and external search
- knowledge retrieval over private documents
- tool and MCP discovery
- skill and procedure loading
- navigation inside long context itself
That last category matters more than it seems. A context window is only useful if the model can find the right thing inside it at the right time. Bigger context windows do not remove search. They just move search inside the model.
The rest of this post walks through each one.
Problem 1: The web was not built for agents
Let's start with the obvious version of the problem: web search.
Agents need web search for very ordinary reasons:
- a personalized daily digest has to know what happened today, not at pretraining cutoff
- a market-monitoring agent has to track competitor pricing, product launches, and changelogs
- a research agent has to verify claims against primary sources
- a shopping or travel agent has to compare pages that change constantly
- a coding agent has to read the latest docs, issues, and release notes
In other words, the minute the task depends on freshness, verification, or public evidence, the agent needs the web.
Most teams assume this part is already solved. Add a built-in web search tool, get citations back, move on.
But web search for an agent is not a simple lookup. It is a pipeline:
- come up with the right query
- pick the right source
- actually load the page
- render it if JavaScript is involved
- extract the useful part from noisy HTML
- decide whether the evidence is enough
- refine the query and try again if needed
Any one of those steps can fail.
Consider a founder building a competitive intelligence agent. The agent finds the right company page. The page is JavaScript-rendered. Cloudflare is blocking the headless browser. The content that matters is behind a soft login wall. The web search tool returned the URL. Getting what is actually on the page is a different product entirely, which is why Browserbase sells stealth mode, CAPTCHA solving, proxies, and even highlights its Cloudflare signed agents work. That product exists because the failure mode is real and systematic.
Agents do not browse the web the way humans do. They negotiate with it.
The managed web search tools from frontier labs such as OpenAI, Anthropic, and Google are useful. They return citations, handle some of the pipeline, and are now billed as explicit line items separate from model tokens. OpenAI and Anthropic both price web search at $10 per 1,000 searches. That pricing signal matters. The industry has already admitted that retrieval is not some free background utility. It is its own product surface with its own cost structure.
But even with those tools, the hard part is not fully solved. Provider-native search is great when you want "an answer with citations." It is much weaker when you need repeated monitoring, raw page access, extraction from messy sites, deeper iteration, or a reliable fetch primitive inside your own agent stack. A competitor-tracking agent, for example, does not just need a summarized answer. It needs the actual pricing page, the changed sections, maybe the FAQ, maybe the release notes, and often the raw content for comparison over time.
That gap is exactly why Firecrawl, Exa, Tavily, and Parallel exist. Firecrawl's own search API exposes scrapeOptions because "find the page" and "get the useful content" are different operations. Parallel makes the same point from another angle: its Search API is pitched as collapsing the traditional search -> scrape -> extract pipeline into one API, and its Search MCP exposes web_search and web_fetch as the basic primitives for agents. Their product language is useful because it indirectly admits the same thing: agent search is not just ranking links. It is discovery plus access plus extraction plus compression for the next reasoning step.
Problem 2: RAG solved the easy slice
Now let's move one layer inward.
The first generation of retrieval-augmented generation made the problem look tractable. Embed your documents, store vectors, retrieve the top-k most similar chunks, append them to the prompt. For narrow, well-scoped, single-hop questions over a clean corpus, this works.
It breaks on anything harder.
Suppose you build a technical QA system over internal docs. Single-hop questions work well. Then someone asks a question that requires connecting a constraint described in one document with a definition from another and a caveat buried in a third. Cosine similarity returns three chunks that look individually relevant, but they do not compose into an answer. The model finds each piece, but the retrieval step never actually bridges the gap between them.
This failure is not accidental. It is structural. Similarity is not the same as usefulness. A chunk can be semantically close to a query and still be useless for the final answer. Another chunk can look semantically distant and still be essential for a reasoning step three hops later. This is exactly why IRCoT (interleaving retrieval with chain-of-thought, ACL 2023) and Self-RAG exist as research directions. One-shot retrieve-then-read hit a real ceiling, so the field moved toward iterative and adaptive retrieval.
So the evolution is straightforward:
- simple RAG: retrieve once, read once
- better RAG: retrieve, reflect, and try again
- agentic RAG: break the problem apart, search in parallel, merge evidence, decide whether more search is needed
This is why "agentic RAG" is now becoming a product surface, not just a paper idea. Azure AI Search now has agentic retrieval, where an LLM breaks a complex query into smaller subqueries, runs them in parallel, and merges the result. Their own example is basically a multi-hop retrieval problem in plain English: "find me a hotel near the beach, with airport transportation, and that's within walking distance of vegetarian restaurants." That kind of query is awkward for classic one-shot retrieval, but much better suited to query decomposition plus parallel search.
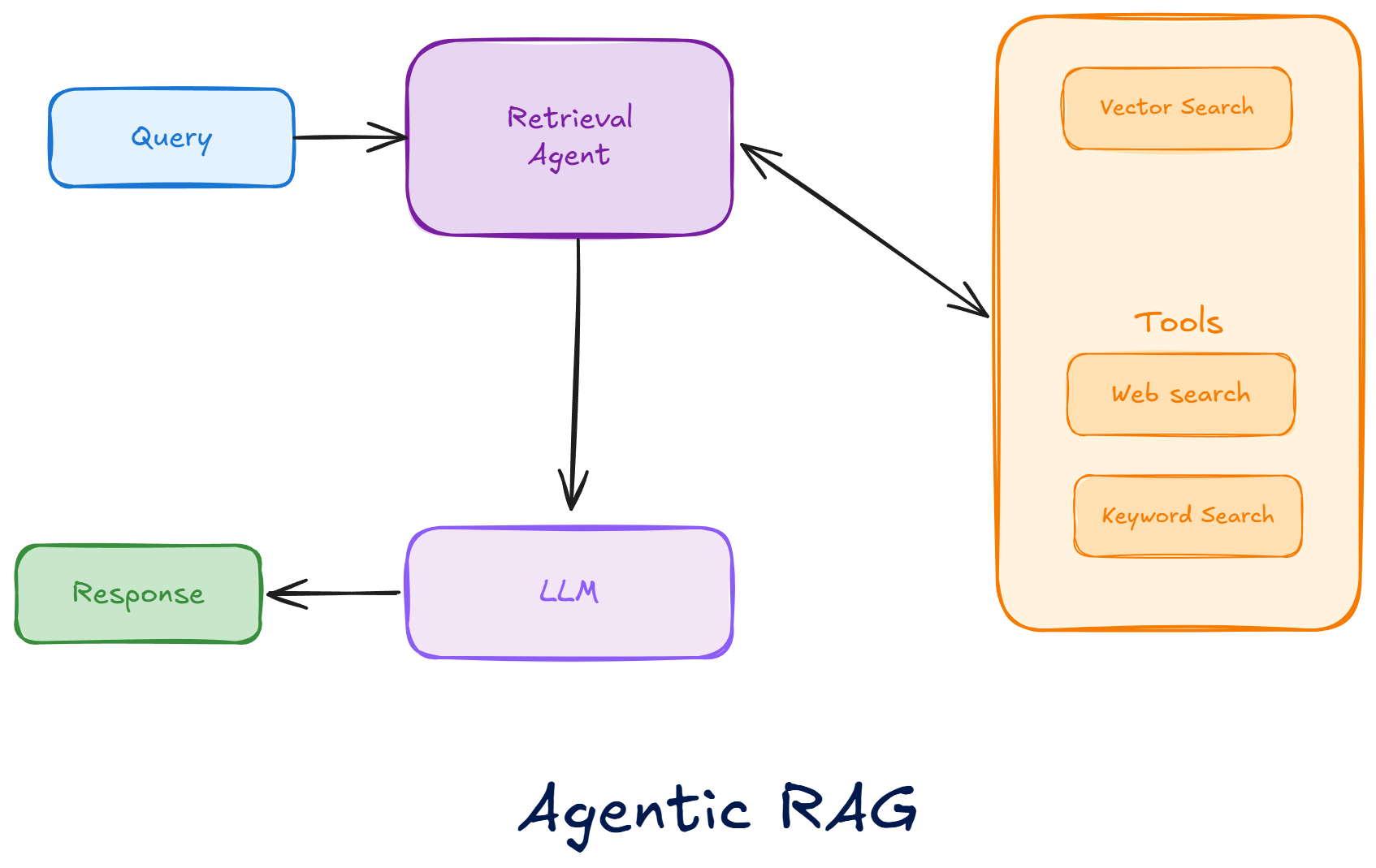
So yes, agentic RAG is solving a real problem. It is helping with multi-hop questions, multi-ask queries, and situations where the original user query is too broad or under-specified for one retrieval pass.
But it is still far from fully solved.
Even after you decompose a question well, a bunch of hard problems remain:
- the needed source might not be indexed at all
- the relevant page might be stale, contradictory, or poorly chunked
- the evidence might live across text, tables, and UI state instead of neat paragraphs
- one subquery can retrieve locally relevant passages that are still useless for the final answer
- the system still has to decide when it has enough evidence and when to keep searching
- each extra retrieval step adds latency and cost
Microsoft's own agentic retrieval docs say the LLM-based query planning adds latency, even if parallel execution helps compensate. That tradeoff is important. Agentic RAG is not a free accuracy upgrade. It is a better search policy with more moving parts.
A very normal real-world example is enterprise support. A user asks: "Does our enterprise plan support SSO for contractors, what changed in the last release, and are there regional limits for EU tenants?" The answer might live across pricing docs, old help-center pages, release notes, and an internal policy page. Agentic RAG is clearly better than one-shot top-k retrieval here because it can break the question apart. But it can still fail if one of those sources is stale, if the important caveat is hidden in a table, or if the retrieval system stops after finding something merely plausible.
And this gets worse as the organization gets bigger.
At small scale, RAG usually fails in understandable ways: bad chunking, weak embeddings, poor prompts. At big-company scale, it starts failing for more boring reasons:
- the same fact exists in five places, but only one copy is current
- permissions mean the best document exists, but the system cannot show it to this user
- different teams store knowledge in different tools with different metadata quality
- highly selective filters improve security but can hurt recall or latency
- constant document churn means the index is always racing reality
- vector storage and query cost stop being abstract and start becoming infrastructure constraints
This is why enterprise search products like Glean keep emphasizing 100+ connectors and real-time permissions-aware retrieval. They are not doing that for marketing decoration. They are reacting to the actual shape of the problem inside big companies: knowledge is fragmented across Slack, Confluence, Jira, Google Drive, Notion, wikis, tickets, PDFs, and internal apps, and the permission model is part of retrieval, not an afterthought.
Even the lower-level search infrastructure shows the same pain. Azure AI Search's vector filter documentation explicitly calls out a tradeoff between filtering, recall, and latency, and notes that some filter modes can produce false negatives for selective filters or small k. That matters a lot in enterprises because security and access control are often implemented as filters. So the retrieval system is not just trying to find the most relevant passage. It is trying to find the most relevant passage among the subset this user is allowed to see, while still being fast enough to feel interactive.
There is also a scale tax on the index itself. Azure documents vector index size limits and storage tradeoffs because large corpora consume memory and can require multiple stored copies depending on the workload. So even before the model starts reasoning, the retrieval layer is already trading off freshness, cost, recall, latency, and access control. A very normal enterprise question like "What is the current travel reimbursement policy for contractors in Germany?" can span an HR PDF, a newer policy page, a regional addendum, a legal exception in shared drive, and a stale Slack workaround. The hard part is not generating the answer. The hard part is finding the newest authoritative source and ignoring the plausible but outdated ones.
RAG treated retrieval like a database lookup. Agentic systems reveal that retrieval is closer to exploration.
Problem 3: MCP and tools moved the problem up the stack
The Model Context Protocol gave agents a standard way to connect to tools. This is genuinely useful. It also made something more obvious: tools themselves are now a search problem.
Once an agent has access to fifty or more tools, it runs into a familiar problem in a new form. Which tool is relevant? Which action name is correct? Is authentication already set up? Which capabilities should even be visible right now?
Anthropic's own advanced tool use documentation puts a number on this: large tool catalogs can push tool definitions past 50,000 tokens before the model has even read the user's request. Their recommended fix is to use a smaller retrieval model to return only the relevant tools based on user intent, and even use semantic search over tool descriptions. That recommendation is RAG. For actions.
And the ecosystem is already moving in that direction. Anthropic's own advanced tool use engineering post says agents should "discover and load tools on-demand" instead of stuffing every definition into context upfront. LangGraph added dynamic tool calling so the available tools can change at different points in a run. Their examples are telling: require an auth tool before exposing sensitive actions, start with a small toolset, then expand as the task evolves. Salesforce's DX MCP blog makes the same move with toolsets, noting that hosts can dynamically load only the tools they need to minimize memory use and improve performance.
That is the deeper point. The problem is not just "which tool should the model call?" The problem is also "which tools should even be attached right now?" Static attachment made sense when agents had a handful of tools. It breaks down when the catalog is large, sensitive, or step-dependent. So now we are seeing dynamic tool attachment, scoped tool exposure, and tool retrieval as separate design patterns.
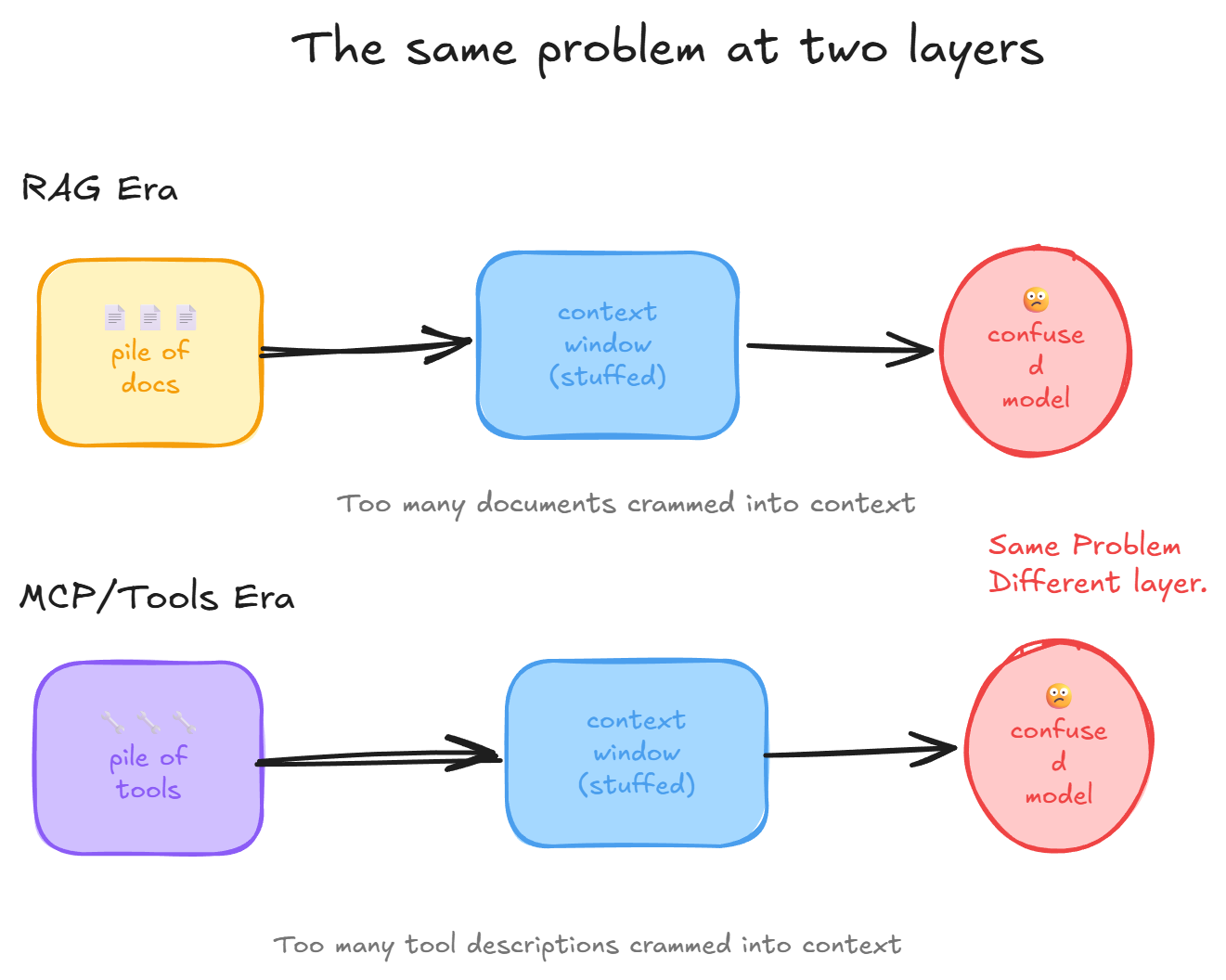
We solved document overload by inventing retrieval. Now we are rebuilding the same fix for tools. Composio's Tool Router, which explicitly searches, plans, and authenticates across tool ecosystems, is basically a retrieval layer for actions. Even outside product docs, the ecosystem keeps describing the same pain: Apify recently summarized the MCP moment as context overload, auth pain, and failed tool calls everywhere. Once you have enough MCP servers, you need search to find your search tools.
Problem 4: Skills are workflow search
At this point, there is one more kind of thing the agent needs to find: workflow.
Agents do not just lack facts and tools. They also lack reusable, environment-specific know-how.
Using Skills well is a skill issue.
— Thariq (@trq212) March 17, 2026
I didn't quite realize how much until I wrote this, the best can completely transform how your team works. https://t.co/a0kbhdHdyf
Consider a coding agent that needs to deploy to an internal infrastructure with custom build flags, a non-standard CI configuration, and a known workaround for a flaky pre-push hook. None of this is in pretraining. Without a skill, the agent has to rediscover the workaround by trial and error every time. It burns tokens, fails steps, and eventually needs help. With a skill, it loads the procedure on demand, executes it, and moves on.
Skills are what happens when you stop making the agent rediscover the same workflow every turn.
This is also where the ecosystem is starting to converge on a few file-level conventions.
At the project layer, we now have dedicated memory files such as AGENTS.md and CLAUDE.md. They look similar, but they are solving a slightly different problem than skills.
AGENTS.mdis emerging as a simple open format for repo-level instructions for coding agents- OpenAI explicitly recommends
AGENTS.mdfor Codex so the agent can learn repo conventions, testing commands, and project-specific gotchas - Anthropic uses
CLAUDE.mdas Claude Code's project memory, with a hierarchy that can include enterprise, project, and user-level memory files
These files are useful, but they are not the whole answer. They are mostly always-on project memory. Skills are more selective. They are a way to package a reusable capability so the agent can discover it and load it only when needed.
The core issue is simple: you cannot stuff every workflow into the prompt. OpenAI's own Codex engineering write-up says the "one big AGENTS.md" approach failed and that AGENTS.md works better as a map than as an encyclopedia. That is the same pattern we keep seeing everywhere else. Once the context gets large enough, the problem becomes navigation again.
So the stack is starting to separate into two layers:
AGENTS.md/CLAUDE.mdfor always-on project memorySKILL.md/skill.mdfor workflows that should be loaded on demand
That second layer is getting standardized too. OpenClaw treats skills as Agent Skills-compatible folders, the Agent Skills specification defines SKILL.md with progressive disclosure, Vercel's skills ecosystem is pushing the same format across agents, and Mintlify now auto-generates skill.md for docs. The reason this works is straightforward: Hermes uses progressive disclosure for skills because not every workflow should live in prompt context all the time. Some workflows need their own retrieval layer.
Documents answer what is true. Tools answer what can I do. Skills answer how should I do it here.
Problem 5: A bigger context window is a larger search space
Now for the part I think people still under-appreciate: context itself.
The common response to long-context failures is simple. If the model cannot find the relevant information, give it a bigger context window. This framing is almost exactly backwards.
A larger context window does not automatically improve the model's ability to locate what matters inside it. It increases the size of the space the model has to navigate. The bottleneck is not room. It is navigation.
Consider a research agent processing a 200-page technical report. The binding constraint appears on page four. The answer that depends on it is on page 180. The model can individually look at both sections and still fail to connect them. This is basically the "lost in the middle" problem: relevant information buried inside a long input is used less reliably than information near the edges.
And once you look at real agent products, you can see that everyone has quietly accepted this. Nobody is relying on "just make the window bigger" as the only answer anymore. They are all building context-management systems on top.
The choices differ by provider, but the pattern is the same.
- OpenAI is leaning into native compaction. In the Codex stack, the conversation gets compacted automatically once it crosses a threshold. Their newer
/responses/compactflow does not just replace old messages with a plain-English summary; it returns a smaller list of items plus a special compaction item intended to preserve more of the model's latent understanding across context-window boundaries. That is a very specific design choice: compress the past, keep the task moving, and treat context management as part of the runtime. - Anthropic exposes compaction much more directly at the product layer. Claude Code has auto-compact, a manual
/compactcommand, optional focus instructions like/compact Focus on code samples and API usage, and evenCLAUDE.mdhooks for custom summary instructions. That is a different design choice: context compaction is explicit, steerable, and summary-driven. - Google has pushed harder on a different axis: very large context windows and context caching. Gemini 3 emphasizes 1M-token context, and the Gemini API has both implicit and explicit context caching so repeated prefixes can be reused across requests. Gemini CLI also emphasizes checkpointing to save and resume longer sessions. That is not exactly the same as compaction, but it is still a context-management strategy. Instead of aggressively shrinking the conversation, it tries to give you more room, reuse the expensive prefix, and resume work when needed.
So the choices are different:
- bigger windows
- summarization and compaction
- checkpointing and resume
- persistent project memory files
- cached prefixes across requests
But all of them are really answers to the same question: how does the agent keep the right parts of history available without drowning in the whole history?
This is why Recursive Language Models introduce explicit navigation operators such as peek, partition, grep, and zoom instead of just extending sequence length forever. Those are search operations over context. Related work like LCM makes the same point from another angle: long context and local search need to work together. Once you look at it this way, recursive context methods start looking less like magic context scaling and more like retrieval policies over an internal search space.
Context engineering is just search engineering with better marketing.
Conclusion: Search keeps coming back
Search keeps showing up everywhere: on the public web, inside RAG systems, across tool and MCP catalogs, inside skills and workflow loading, and even inside the context window itself.
That is why so many people are attacking the problem from different angles. Some are building better web-search stacks. Some are building agentic RAG. Some are building tool routers and dynamic attachment. Some are building skills, memory files, compaction, caching, and context-navigation systems. They all look different, but they are all trying to solve the same thing.
If agents can reliably solve search across all of these surfaces, that would be a huge capability jump. It would mean they can consistently find the right evidence, the right tool, the right workflow, and the right context before acting. That gets us much closer to agents that feel robust, general, and meaningfully closer to AGI in practice.
Can anyone turn web search, knowledge retrieval, tool discovery, workflow/skills loading, and context navigation into one coherent search runtime for agents, or is this the hard part that keeps standing between today's agents and something much closer to AGI?
References:
- Apify X post on MCP pain: x.com/apify/status/2011556498477105383
- Agent Skills: Specification
- AGENTS.md: Open format
- Anthropic advanced tool use guide: Tool use implementation
- Anthropic engineering: Advanced tool use
- Anthropic Claude Code memory: CLAUDE.md memory
- Anthropic Claude Code costs: Compaction and auto-compact
- Anthropic Claude Code slash commands: Slash commands
- Azure AI Search: Agentic retrieval
- Azure AI Search: Vector filters
- Azure AI Search: Vector index size
- Azure AI Search: Vector storage options
- Browserbase Cloudflare post: Browserbase + Cloudflare
- Composio Tool Router: Tool Router API
- Firecrawl search docs: Search API
- Glean: Enterprise search engine
- Gemini 3: 1M context window
- Gemini API: Context caching
- Gemini CLI: Checkpointing and GEMINI.md
- Hermes skills: Progressive disclosure
- IRCoT, Trivedi et al. (ACL 2023): Interleaving Retrieval with Chain-of-Thought Reasoning
- LCM: Long Context Models and local search
- LangGraph: Dynamic tool calling
- Mintlify: skill.md
- OpenAI: How OpenAI uses Codex to build Codex
- OpenAI: Harness engineering for an agent-centric world
- OpenAI: Unrolling the Codex agent loop
- Self-RAG, Asai et al. (NeurIPS 2023): Self-RAG: Learning to Retrieve, Generate, and Critique
- Salesforce DX MCP: Dynamic toolsets
- Lost in the Middle, Liu et al. (TACL 2024): How Language Models Use Long Contexts
- OpenClaw skills: Skills docs
- Parallel Search API: Search quickstart
- Parallel Search MCP: Search MCP
- Parallel Search product: Parallel Search
- Recursive Language Models: Paper · Repo
- Vercel: Introducing skills
- Browserbase stealth mode: docs.browserbase.com/features/stealth-mode